The most interesting thing I learned today is how hard tokenzation (as in lexical analysis) really is. At first I thought that it was just as simple as dropping off punctuation marks as demonstrated by Python ntlk library.
from nltk.tokenize import sent_tokenize, word_tokenize
data = "All work and no play makes jack a dull boy, all work and no play"
print(word_tokenize(data))
Out: ['All', 'work', 'and', 'no', 'play', 'makes', 'jack', 'dull', 'boy', ',', 'all', 'work', 'and', 'no', 'play']
Yes the nltk did literally “tokenize” it in the literal definition of just grouping some sections of string together. But it might not consider the semantic of the tokenization. One easy example is Joe Carter goes to Standford University. Shall we treat Joe and Carter as a separate token or Joe Carter as a token? Same cases applies for Standford University.
It does not stop there. How about Mr. O’Neill? Which of this tokenization of O'Neill is correct? neill? oneill? o'neill? o' and neill? o and neill? How shall we treat hyphenation in Joe's state-of-the-art solution?, the kick-off meeting, and https://example.com/some-url-with-hyphen?
And it is still even just English/Latin text. Most monosyllabic languages (like Vietnamese, Chinese) don’t even have white space between “words”.
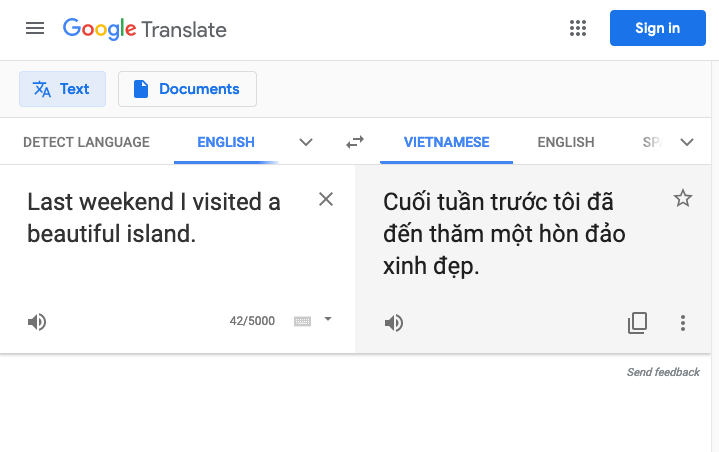
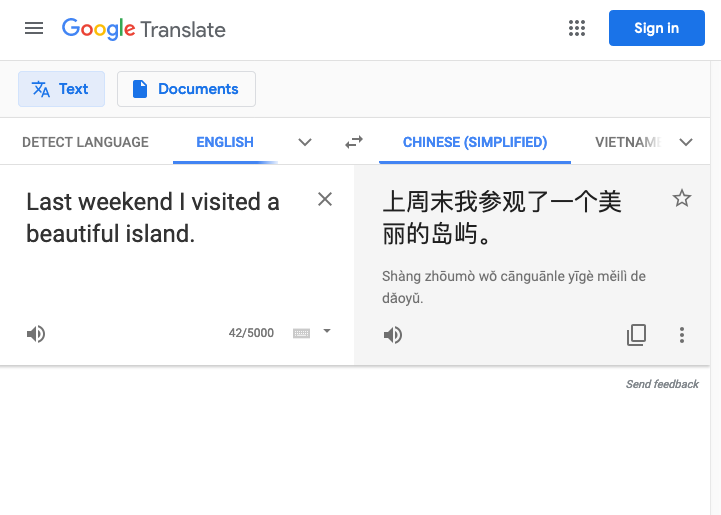
(Read more at: section 2.2 of Introduction of Information Retrieval by Manning.)